My proposal was to develop a feature for the kw project that served as a hub for patches in https://lore.kernel.org, an archive for public mailing lists related to Linux kernel.
This feature is named kw patch-hub, and this blog post is a “final report” of my GSoC23
contributions.
Non-related Contributions
This first section describes my contributions to kw that are not directly related to the
kw patch-hub feature but were part of my GSoC23. Nonetheless, these were important in
their own context and made me more in sync with kw coding style, its contribution model,
and, most importantly, with my mentors and people around the project (which I found most
invaluable).
Adding Support for Native Zsh Completions
I contributed meaningful changes to kw project during the application period. My first
significant contribution (both in scope and number of commits) was adding support for
native Zsh completions. Without getting into too much detail, each Shell, say, Bash, can
provide command completions. In other words, it’s the well-known behavior of hitting TAB
and waiting for the Shell to either complete the command you are typing or show possible
completions.
These completions are Shell-dependent, and kw only had native support for Bash completions. Zsh completions were adapted from the native Bash completions, but this “emulation” didn’t work and resulted in broken completions for Zsh. This was a waste, as the Zsh completion system provided deeper features than Bash, like highlighting options shown, coupling documentation with options shown, and more.
During February I worked on bringing kw support for native Zsh completions. I described this in further detail in an earlier post, but you can see the full Pull Request with 29 commits by clicking here. To illustrate, below is a demo of the results achieved.
Introducing SQLite3 to kw
From before the Community Bonding Period began until halfway through it (from mid-April to mid-May), I worked on introducing the Database Management System (DBMS) SQLite3 to kw. This was a long-awaited addition for the kw community, as it would improve the project’s scalability and allow the collection of statistics.
I discussed this in further detail in an earlier post and the full Pull Request with 14 commits representing this contribution can be accessed here.
I really want to stress that I didn’t work on this contribution alone, as the whole database schema was made by Rubens Gomes Neto and Magali Lemes, and the base of the migration script and library functions was made by Rubens Gomes Neto. My work was built upon theirs and I worked on refining little details of the schema, finishing the migration script, and, mainly, integrating the database all around the project.
Other Non-Related Contributions
Throughout the year, I also contributed all around the kw project. Below is a list of every merged Pull Request concerning other work not related to my main GSoC23 project. Note that these PRs appear as Closed, but that is because the project’s maintainers clone the PR locally, commit themselves the changes, and close the PR.
kw patch-hub
My project focus was to add a feature to kw that was a terminal-based User Interface to
the https://lore.kernel.org archives with patch-reviewing in mind. In my proposal, I
listed the following deliverables for kw patch-hub:
- A user-friendly interface to patchsets in the lore archives.
- Capabilities of downloading, applying, building, and deploying patchsets.
- Capabilities of replying patchsets in the public mailing lists with Reviewed-by, Tested-by, and inline reviews.
I use the term patchset instead of patch, because a patchset is a logical set of patches pertaining to the same context, while a patch is any individual change sent as a message. For reviewing, considering chunks of related changes instead of individual changes makes more sense. Just think of reviewing a Pull Request in its whole context, versus reviewing the commits of this PR independently.
First Cycle: Understanding the Problem and Building the Core
Since my proposal, my better understanding of the problem at hand along with my interactions with my mentors, made me realize that the most important deliverable was to provide a reliable UI to lore.
We didn’t plan on having strict development cycles, but looking in hindsight, I can
divide my work on kw patch-hub into 3 development cycles. The first cycle was related
to experimenting and understanding the problem and building the feature’s core.
How we kept Organized
From an organizational perspective, we documented every starting requisite in issues and added them to a GitHub Kanbam board. Below is a print of it, just for illustration purposes, but you can check its live state here.
Every time we encountered some kind of bug, or discussed/thought of a possible improvement, we added an entry to the ‘To Do’ list, even if was just a draft that would promptly altered or removed. This sort of “protocol” was really important to keep track of what needed to be done.
Studying and Expanding the Code
From the code perspective, I focused on understanding what was already done, what needed
to be done, what needed to change, and built the core of kw patch-hub. About two years
ago, my mentors Rodrigo Siqueira and Melissa Wen
implemented what we can call the “predecessor” of kw patch-hub named kw upstream-patches-ui.
This was mostly a prototype that validated the feature, but that laid the foundation
needed for my project.
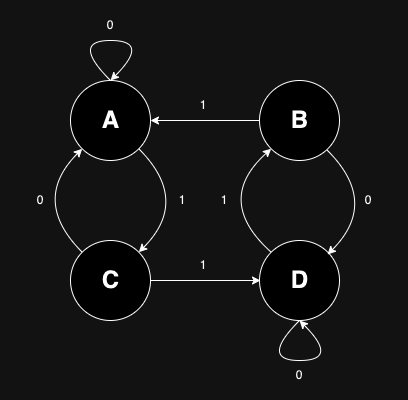
At the end of this cycle, kw patch-hub started to look functional and the feature
software architecture was somewhat solidified (although, as we will see in a moment,
kind of messy). At that moment, the feature was still named kw upstream-patches-ui
and looked like this:
Contributions of First Cycle
From mid-May up until mid-June, those were my contributions in the form of Pull Requests, in chronological order of merge:
In this cycle, we also worked on a PR for integrating
kw patch-hubwithkw build. We came to a working version but decided to not introduce this enhancement before cleaning the code. Nevertheless, this PR produced some good commits that were merged into the project:
- src: lib: dialog_ui.sh: Add ‘Yes/No’ prompt screen
- src: lib: kw_string: Add function for converting string to filename
- src: lib: dialog_ui: Add function to create ‘File Selection’ screen
Time to Clean
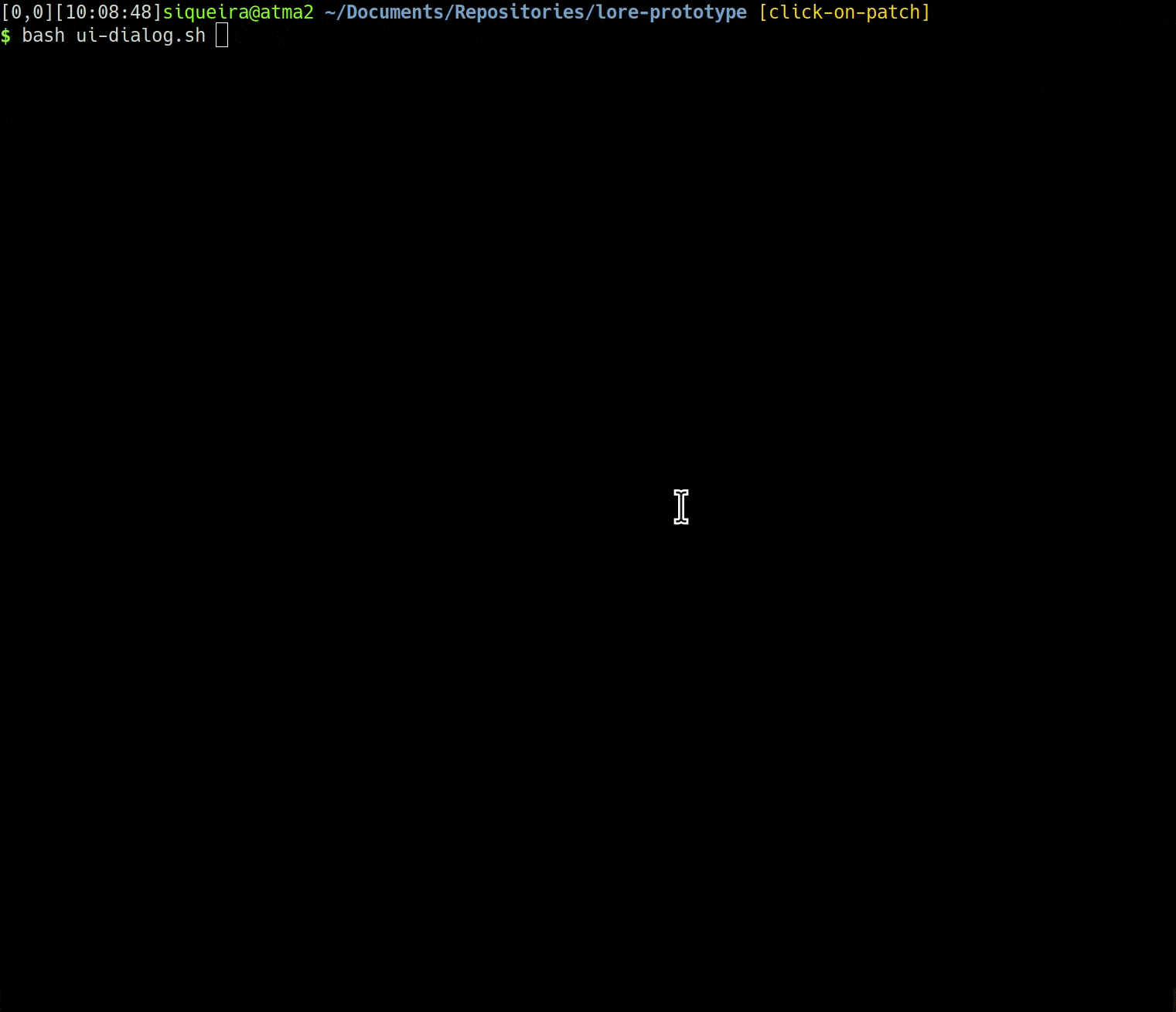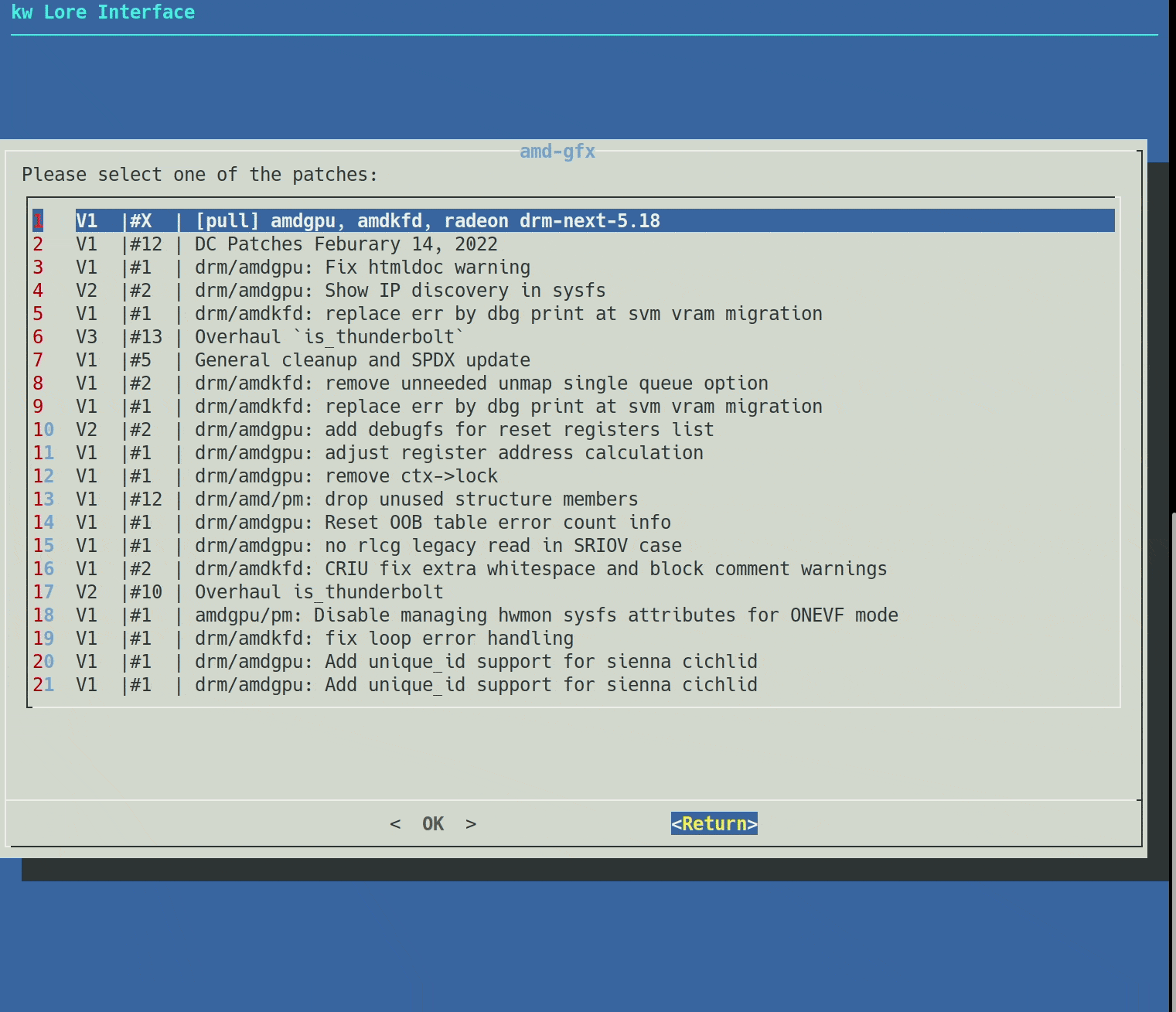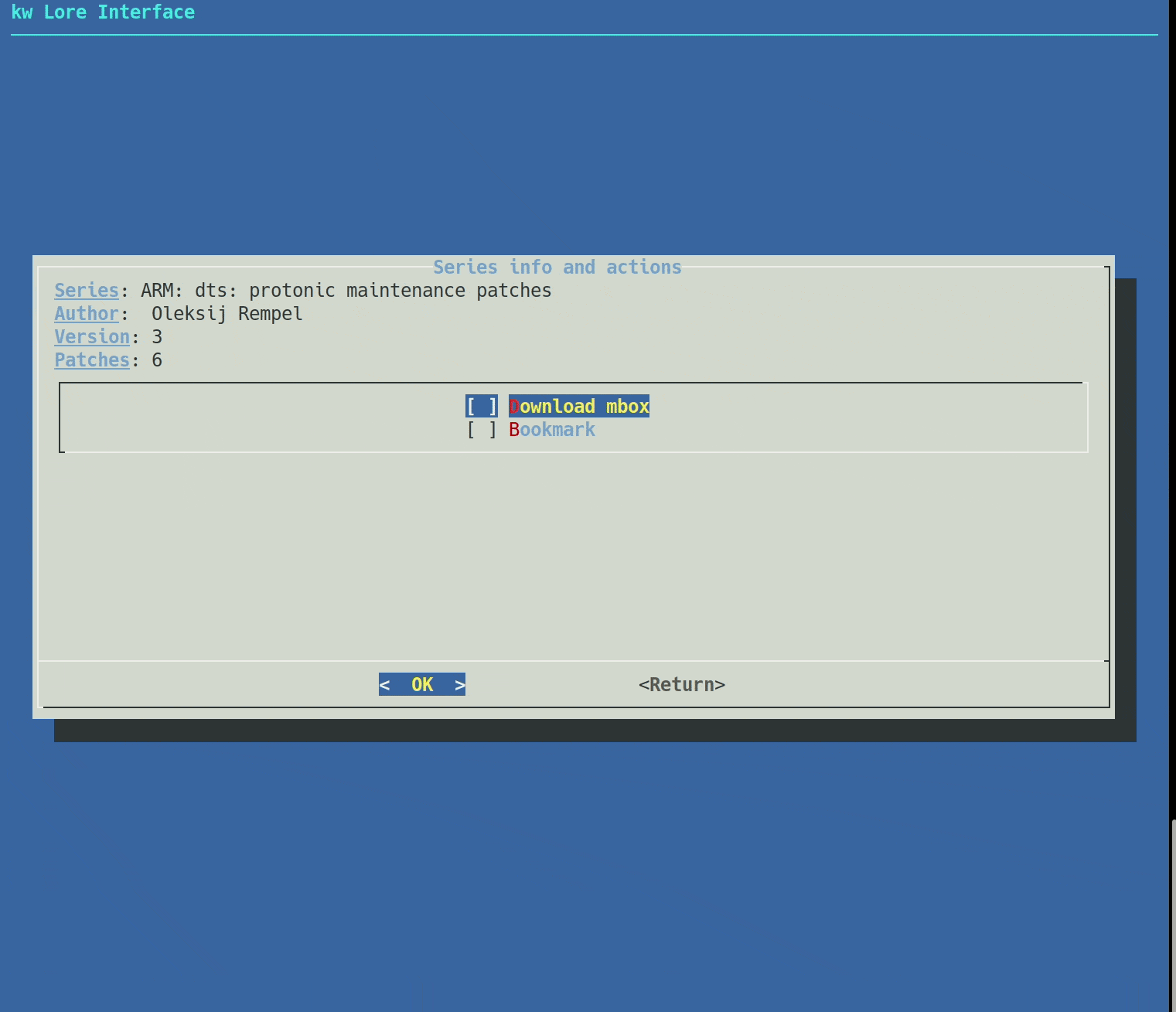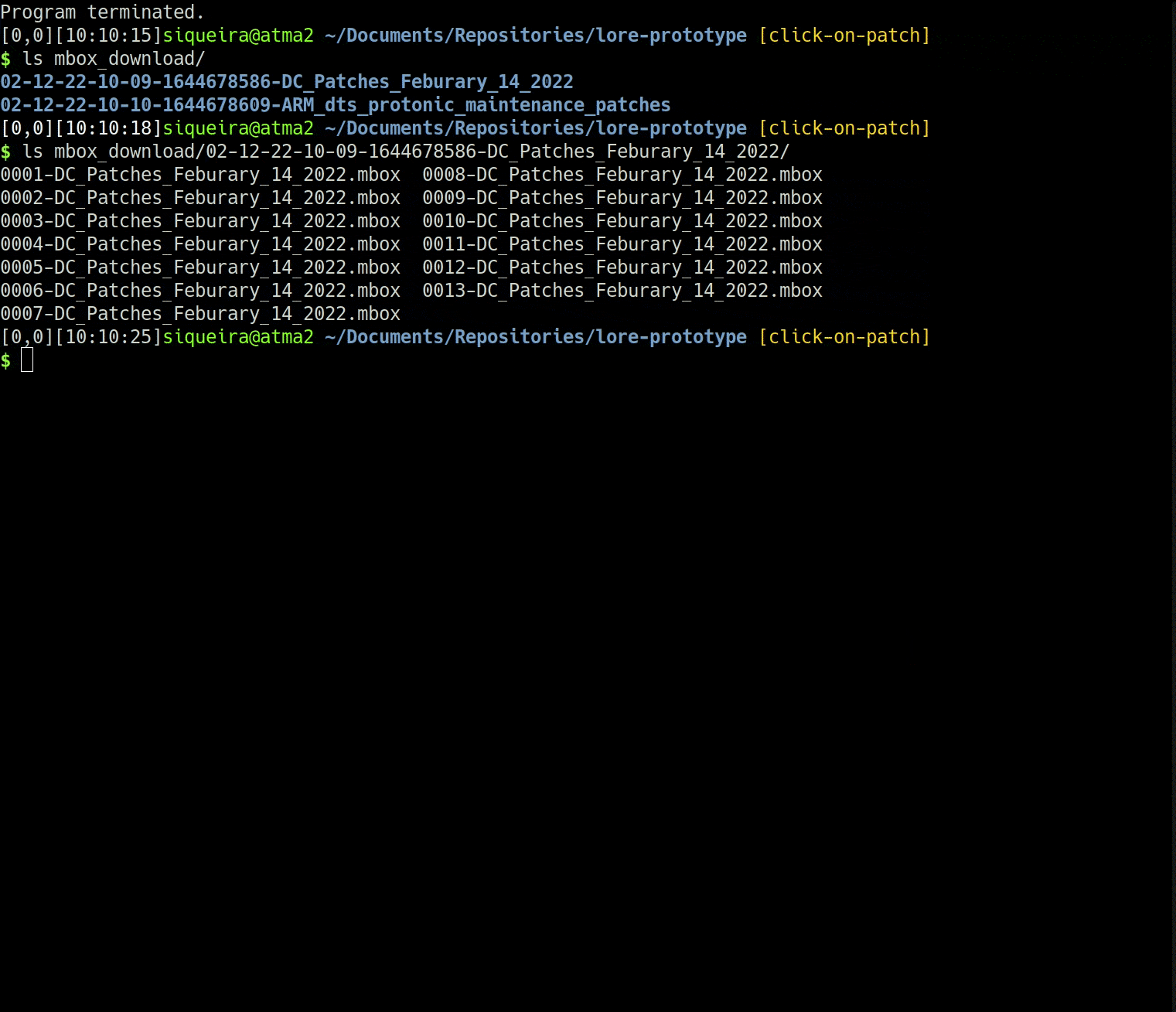
kw patch-hub had its core screens implemented (Dashboard, Registered Mailing Lists,
Bookmarked Patchsets, Settings, Latests Patchsets), but it lacked a reliable fetch
strategy of patchsets from lore, that limited patchsets from a hardcoded period of
time, and the whole feature needed a refactoring, as its architecture was starting
to break and the code had some bad smells.
Second Cycle: Refactoring
As mentioned, kw patch-hub had a core implemented, however, the feature badly
needed refactoring.
At this point, the feature was implemented across three files: 2 library files
(src/lib/lore.sh and src/lib/dialog_ui.sh) and one that represented the feature
itself (src/upstream_patches_ui.sh). The Model-View-Controller was softly implemented
in a way that src/lib/lore.sh was the Model, src/lib/dialog_ui.sh was the View, and
src/upstream_patches_ui.sh was the Controller.
Refactoring the Controller
I described in a previous post
the Finite-State Machine computation model used to implement kw patch-hub Controller,
but the thing was that for each new state added, src/upstream_patches_ui.sh grew
uncontrollably. At one moment, the file was more than 500 lines in size with functions
that didn’t follow a logical order, which made it harder and harder to scroll to the
desired line each time an addition was made. To exemplify the need for refactoring on
this Controller front, there was a switch-case with more than 100 lines.
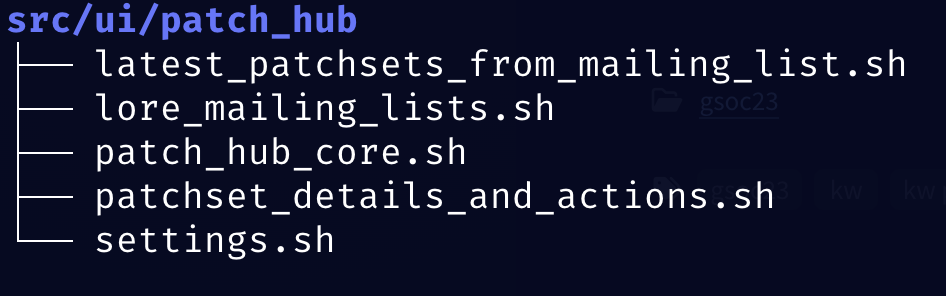
The Controller refactoring was made by taking advantage of the Finite-State Machine model implemented and breaking down the file into smaller files that roughly represented the states. Thanks to these extractions that resulted in great modularity, both maintaining and expanding the feature was made much easier from this point onward, as I could isolate problems to single files, lower the complexity and coupling of the code, whilst also introducing somewhat of a pattern for Finite-State Machines to kw project.
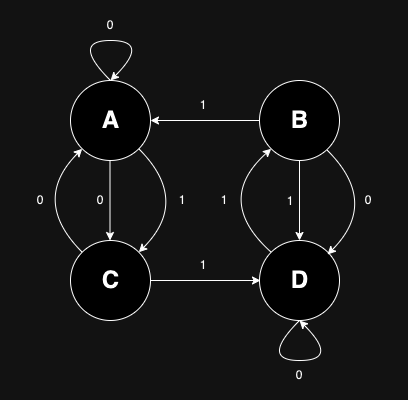
Now the Controller files are stored in src/ui/patch_hub and look like this:
Refactoring the View
Another badly needed refactoring was in the View front. The file src/dialog_ui.sh
mostly stored library functions to create dialog
boxes. These dialog boxes are the means through which kw patch-hub displays screens,
hence, the View role the file performed (it is worth noting that this role is from
kw patch-hub perspective, as the library file should be general enough to be used
all around the kw project).
These functions were really similar and two actions that were exactly the same in each and every one of them were: building the preamble of the dialog command and evaluating the dialog command built. These two actions were extracted to functions, reducing a lot of duplicated code, whilst also allowing for more fine-grained testing. In the refactoring, I took the opportunity to also enforce some patterns in the View.
Defining the feature’s new name
This may not be a refactoring, but as we are essentially changing names to improve the
feature, I will consider it here. The name change was urged since the start of GSoC,
and in this second cycle moment, we decided to pull the trigger. I opened a poll
to decide the feature’s new name and kw patch-hub was elected.
Contributions of Second Cycle
From mid-June up until the start of August, those were my contributions in the form of Pull Requests, in chronological order of merge:
Third Cycle: Consolidating Interaction with Lore API
After the two first cycles, we tackled what was considered from the onset of the program the critical point: the interactions with lore API, especially to fetch an arbitrary number of patchsets reliably, allowing the user to potentially navigate all of a mailing list history. It is important to note that, in case this problem couldn’t be solved, the whole feature would be jeopardized as its functionality would be really limited.
The Problem and the Solution
I plan on making a more detailed post on the lore API, but in summary, lore provides a search engine powered by Xapian that allows us to make queries to match specific messages in a given public mailing list archived.
The implementation, at this point, used a hardcoded period of time (last 2 days) to query lore for patches and we needed a way to fetch adjacent chunks of patchsets that had a consistent order.
After deeply studying the lore API, or, should I say, reverse-engineering it, I came up with an answer that both solved the problem and eliminated the need for managing timestamps to get consistent chunks of patchsets.
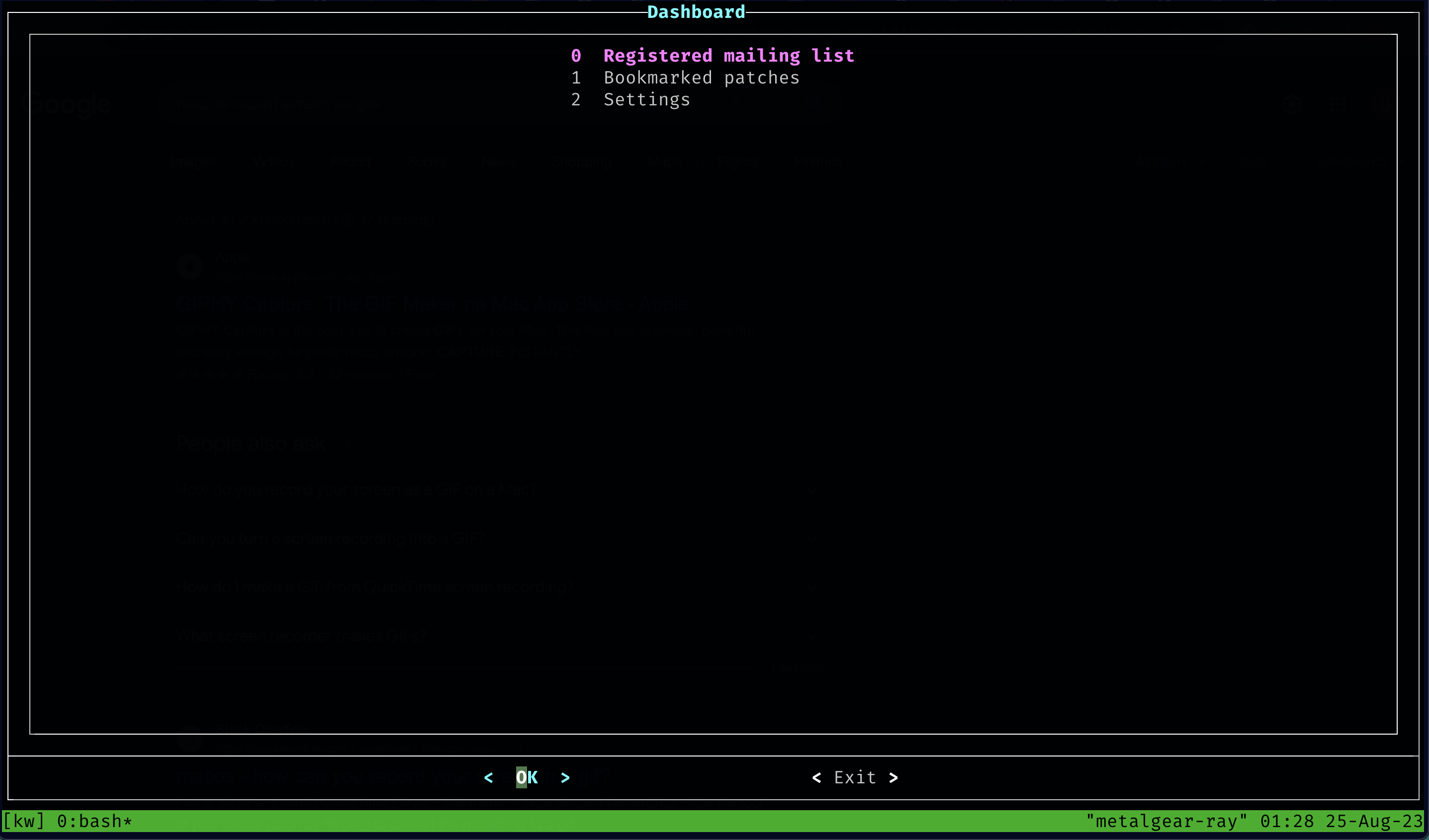
Current Merged State of kw patch-hub
All this blabber aside, below is a demo of using kw patch-hub to navigate through
the amd-gfx list history. This demo is the current merged state of kw patch-hub.
Notice that the feature paginates the patchsets and doesn’t do redundant fetches when
going back on pages.
Contributions of Third Cycle
This whole cycle is contained on this Pull Request with 9 commits that was active from the start of August until some days ago:
kw patch-hub: Add reliable fetch of latest patchsets from mailing list
Next Steps
As a result of my GSoC project, kw patch-hub can be used as a reliable UI to
the lore archives and provides some other functionalities like bookmarking patchsets,
downloading applicable patchsets (to a default or custom directory), and managing
the feature’s settings through the feature itself.
It’s important to note that kw patch-hub has become an integral part of my Capstone
Project, so I’ll keep updating the feature until the end of this year, and probably
further than that.
Here is a list, not in order of importance, of the next steps to take that will make
kw patch-hub incrementally better. By tackling all of these, I firmly believe the
feature will provide a solid experience for users, especially for patch-reviewing.
- Optimize fetch time. In the demo GIF above you can see that loading times are not good.
- Fix parsing of patchsets. In the demo GIF above you can see some patchsets metadata malformatted/incorrect.
- Add an ‘Apply’ action for patchsets.
- Add a ‘Build’ action for patchsets.
- Add a ‘Deploy’ action for patchsets.
- Add query based on string. In other words, integrate a more refined search of lore archives on the feature.
- Allow users to reply patchsets with ‘Reviewed-by’, ‘Tested-by’, and with inline reviews.
- Improve feature UX.
- Refine feature fixing bugs.
- Improve loading screens. They are static and don’t give much feedback to the user.
Acknowledgments
First, I want to give special thanks to my mentors Rodrigo Siqueira, Melissa Wen, Paulo Meirelles, and Magali Lemes. They were always very attentive and open to communication. They also were really considerate of me when giving feedback and would often take a step back to explain concepts or point me in the right direction. I couldn’t wish for better mentors, so thank you all so much.
I also want to thank my colleague Aquila Macedo who also actively contributes to kw and was there at every weekly kw meeting.
Finally, I want to thank The Linux Foundation for giving kw and me the opportunity to participate in GSoC23.
]]>