Integration Testing for kw-build
Written by Aquila Macedo , published on August 20, 2024The kw build command is a versatile tool that encompasses everything related
to building and managing Linux kernel images. It supports various options, such
as displaying build information, invoking kernel menuconfig, enabling
ccache, adjusting CPU usage during compilation, saving logs, and using the
LLVM toolchain. Additionally, it provides options for cleaning the build
environment, customizing CFLAGS, and compiling specific commits. The
command also offers alert notifications and verbose mode for detailed debugging
information.
Overcoming the Initial Challenges in kw build Integration Testing
One of the main challenges I’ve encountered while building integration tests
for kw build was the significant time required to compile the kernel, a
notoriously time-consuming task. I configured the integration tests to be
triggered on pushes and pull requests. However, as the number of tests
increases, the execution time on GitHub Actions’ CI also grows, which
eventually will become impractical. The primary reason for this was that the
tests were executed across three different distributions (Debian,
Fedora, Arch Linux). This meant that each test had to be run in all
three distros, which overloaded the execution time.
Given the limitations of the machines available on GitHub Actions, which
are not robust enough to handle the workload required to compile the kernel in
three distinct environments, the best decision at the time was to limit kw
build integration tests to just one distro. It was implemented a function
that randomly selects one of these three distros for each test run. This allows
us to test kw build in different environments while significantly reducing
the time and resources consumed by CI.
Structured Testing Approach with Podman and shUnit2
The integration testing framework for the kw build feature is built using
Podman Containers, which allows us to simulate different environments in an
isolated and controlled manner. To ensure that the functionalities of kw
build are thoroughly tested, the shUnit2 framework is used, providing a
solid foundation for writing and running shell script tests efficiently.
As mentioned in the introductory post about integration testing, shUnit2 offers “magic” functions that simplify the organization and execution of tests. For more details about these features, check out the dedicated post.
Initial Environment Setup: oneTimeSetUp()
Before executing any tests, it’s crucial to correctly set up the environment to
ensure everything is in order. For the integration tests of kw build, this
setup is managed by the oneTimeSetUp() function. This special function is
designed to run once before any test functions (i.e., any function prefixed
with test_). It ensures the test environment is properly configured by
selecting a random Linux distribution, cloning the mainline Kernel
repository, and installing the necessary dependencies. Here’s a detailed look
at how this setup is accomplished:
declare -g CLONED_KERNEL_TREE_PATH_HOST
declare -g TARGET_RANDOM_DISTRO
declare -g KERNEL_TREE_PATH_CONTAINER
declare -g CONTAINER
function oneTimeSetUp()
{
local url_kernel_repo_tree='https://github.com/torvalds/linux'
# Select a random distro for the tests
TARGET_RANDOM_DISTRO=$(select_random_distro)
CLONED_KERNEL_TREE_PATH_HOST="$(mktemp --directory)/linux"
CONTAINER="kw-${TARGET_RANDOM_DISTRO}"
# The VERBOSE variable is set and exported in the run_tests.sh script based
# on the command-line options provided by the user. It controls the verbosity
# of the output during the test runs.
setup_container_environment "$VERBOSE" 'build' "$TARGET_RANDOM_DISTRO"
# Install kernel build dependencies
container_exec "$CONTAINER" 'yes | ./setup.sh --install-kernel-dev-deps > /dev/null 2>&1'
if [[ "$?" -ne 0 ]]; then
complain "Failed to install kernel build dependencies for ${TARGET_RANDOM_DISTRO}"
return 22 # EINVAL
fi
git clone --depth 5 "$url_kernel_repo_tree" "$CLONED_KERNEL_TREE_PATH_HOST" > /dev/null 2>&1
if [[ "$?" -ne 0 ]]; then
complain "Failed to clone ${url_kernel_repo_tree}"
if [[ -n "$CLONED_KERNEL_TREE_PATH_HOST" ]]; then
if is_safe_path_to_remove "$CLONED_KERNEL_TREE_PATH_HOST"; then
rm --recursive --force "$CLONED_KERNEL_TREE_PATH_HOST"
else
complain "Unsafe path: ${CLONED_KERNEL_TREE_PATH_HOST} - Not removing"
fi
else
complain 'Variable CLONED_KERNEL_TREE_PATH_HOST is empty or not set'
fi
fi
}
This method not only prepares the test environment but also establishes a solid foundation for the subsequent tests to be executed efficiently.
Per-Test Environment Setup: setUp()
The setUp() function plays a crucial role in setting up the test environment,
but with a different approach compared to the oneTimeSetUp(). While
oneTimeSetUp() handles tasks that need to be executed only once before all
tests, such as setting up the base environment and cloning the mainline kernel
repository on the host machine, setUp() is called before each individual test.
It contains the sequence of tasks that need to be done before every test in the
test suite (in this case, the kw build integration test suite).
function setUp()
{
KERNEL_TREE_PATH_CONTAINER="$(container_exec "$CONTAINER" 'mktemp --directory')/linux"
if [[ "$?" -ne 0 ]]; then
fail "(${LINENO}): Failed to create temporary directory in container."
fi
setup_kernel_tree_with_config_file "$CONTAINER"
}
Auxiliary Function: setup_kernel_tree_with_config_file()
This function copies the mainline kernel repository to the container, using the temporary path created earlier. This happens once the repository has been cloned on the host machine, optimizing the process for when it’s necessary to implement tests for the three different distributions, allowing the kernel to be cloned only once instead of three times.
This approach saves time and resources, especially considering that cloning the entire mainline kernel repository can be time-consuming.
To ensure that the cloning process is quick and efficient, we opted to clone only the 5 most recent commits from the mainline kernel repository. This is done using the following command:
git clone --depth 5 --quiet "$url_kernel_repo_tree" "$CLONED_KERNEL_TREE_PATH_HOST"
This approach allows testing the most recent changes without the overhead of downloading the entire repository history, saving time and resources.
function setup_kernel_tree_with_config_file()
{
container_copy "$CONTAINER" "$CLONED_KERNEL_TREE_PATH_HOST" "$KERNEL_TREE_PATH_CONTAINER"
if [[ "$?" -ne 0 ]]; then
fail "(${LINENO}): Failed to copy ${CLONED_KERNEL_TREE_PATH_HOST} to ${CONTAINER}:${KERNEL_TREE_PATH_CONTAINER}"
fi
optimize_dot_config "$CONTAINER" "$KERNEL_TREE_PATH_CONTAINER"
}
Auxiliary Function: optimize_dot_config()
This function is then called to configure and optimize the kernel .config file
based on the modules loaded by the Podman container.
function optimize_dot_config()
{
# Generate a list of currently loaded modules in the container
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && /usr/sbin/lsmod > container_mod_list"
if [[ "$?" -ne 0 ]]; then
fail "(${LINENO}): Failed to generate module list in container."
fi
# Create a default configuration and then update it to reflect current settings
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && make defconfig > /dev/null 2>&1 && make olddefconfig > /dev/null 2>&1"
if [[ "$?" -ne 0 ]]; then
fail "(${LINENO}): Failed to create default configuration in container."
fi
# Optimize the configuration based on the currently loaded modules
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && make LSMOD=${kernel_test_tmp_dir}/container_mod_list localmodconfig > /dev/null 2>&1"
if [[ "$?" -ne 0 ]]; then
fail "(${LINENO}): Failed to optimize configuration based on loaded modules in container."
fi
}
Final Test Cleanup: oneTimeTearDown()
The oneTimeTearDown() function is responsible for cleaning up the test
environment after all test functions have been executed.
function oneTimeTearDown()
{
# Check if the path is safe to remove
if is_safe_path_to_remove "$CLONED_KERNEL_TREE_PATH_HOST"; then
rm --recursive --force "$CLONED_KERNEL_TREE_PATH_HOST"
fi
}
This cleanup is crucial to maintaining a consistent test environment and avoiding potential conflicts or failures caused by residual files.
Per-Test Cleanup: tearDown()
The tearDown() function plays a crucial role in ensuring that the test
environment is restored to its initial state after each test function is
executed. This is especially important when a test might modify the state of
the mainline kernel repository within the container. To prevent these
modifications from affecting subsequent tests, it is necessary to clean up and
restore the environment.
function tearDown()
{
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && kw build --full-cleanup > /dev/null 2>&1"
assert_equals_helper "kw build --full-cleanup failed for ${CONTAINER}" "($LINENO)" 0 "$?"
}
The command kw build --full-cleanup executed by tearDown() uses the
--full-cleanup option, which internally runs the make distclean command. This
restores the build environment to its initial or default state by removing all
files generated during the build process, including configuration files and
script outputs. This thorough cleanup ensures that any configuration or
modification made during the test is removed, allowing each subsequent test to
start with a clean and consistent environment, which is essential for the
integrity of the tests.
Practical Examples and Testing Scenarios
Testing kw build Default Functionality
Let’s delve into more details about the standard test for the kw build tool.
function test_kernel_build()
{
local kw_build_cmd
local build_status
local build_result
local build_status_log
kw_build_cmd='kw build'
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && ${kw_build_cmd} > /dev/null 2>&1"
assert_equals_helper "kw build failed for ${CONTAINER}" "($LINENO)" 0 "$?"
# Retrieve the build status log from the database
build_status_log=$(container_exec "$CONTAINER" "sqlite3 ~/.local/share/kw/kw.db \"SELECT * FROM statistics_report\" | tail --lines=1")
# Extract the build status and result from the log
build_status=$(printf '%s' "$build_status_log" | cut --delimiter='|' --fields=2)
assert_equals_helper "Build status check failed for ${CONTAINER}" "$LINENO" 'build' "$build_status"
build_result=$(printf '%s' "$build_status_log" | cut --delimiter='|' --fields=3)
assert_equals_helper "Build result check failed for ${CONTAINER}" "$LINENO" 'success' "$build_result"
}
The test_kernel_build() function performs several checks to ensure that the
kernel build inside the container was successful.
I will break down this test code into parts and explain the flow.
kw_build_cmd='kw build'
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && ${kw_build_cmd} > /dev/null 2>&1"
assert_equals_helper "kw build failed for ${CONTAINER}" "($LINENO)" 0 "$?"
First, the kw_build_cmd variable stores the kw build command, which is the
tool being tested. Then, the command is executed inside the container using the
container_exec() function. In this case, the function will navigate to the
mainline kernel repository directory (located at KERNEL_TREE_PATH_CONTAINER
and run the build command.
The output of this command is redirected to /dev/null to avoid interfering
with the test log.
Verifying the Return Value $?
The check for the return value $? of the kw build command is performed
immediately after execution with the assert_equals_helper function. If the
return value is not zero, indicating a failure, the test fails generating the
error message kw build failed for <container>
Verifying the Build Status in the Database
build_status_log=$(container_exec "$CONTAINER" "sqlite3 ~/.local/share/kw/kw.db \"SELECT * FROM statistics_report\" | tail --lines=1")
After the execution of the kw build command, the next step is to verify
whether the kernel build process was correctly recorded in the kw.db
database. This database is where kw stores logs and statistics about
executions. The container_exec function is used again to execute an SQL
command within the container, retrieving the most recent log from the
statistics_report table.
The statistics_report table contains detailed information about each build
performed, including the build status and the final result. For example:

build_status=$(printf '%s' "$build_status_log" | cut --delimiter='|' --fields=2)
assert_equals_helper "Build status check failed for ${CONTAINER}" "$LINENO" 'build' "$build_status"
build_result=$(printf '%s' "$build_status_log" | cut --delimiter='|' --fields=3)
assert_equals_helper "Build result check failed for ${CONTAINER}" "$LINENO" 'success' "$build_result"
The data retrieved from the database is processed to extract the build status
and result. Using the cut command, the build status is extracted from the
second column of the log, and the final result from the third column.
These values are then compared with the expected ones. The status should be
equal to build, indicating that the build process was started and recorded
correctly. The final result should be success, confirming that the build was
completed successfully.
Testing kw build with –cpu-scaling option
The --cpu-scaling option of kw build allows you to control how much of the
CPU capacity should be used during the kernel compilation. For example, if
you want the compilation to use only 50% of the CPU cores to avoid
overloading your system while performing other tasks, you can use the command:
kw b --cpu-scaling=50
In rough terms, this option adjusts the percentage of the CPU the kernel compilation will use, allowing you to balance the compilation performance with the overall system load.
Testing this functionality of kw build differs from others because we don’t
need to compile the kernel completely to verify if the --cpu-scaling option
works as expected. The goal here is to check if the CPU is indeed being
used in the defined proportion (in this case, 50%). The testing approach is as
follows:
function test_kernel_build_cpu_scaling_option()
{
local build_status
local build_result
local build_status_log
local cpu_scaling_percentage=50
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && kw_build_cpu_scaling_monitor ${cpu_scaling_percentage} > /dev/null 2>&1"
assert_equals_helper "kw build --cpu-scaling 50 failed for ${CONTAINER}" "(${LINENO})" 0 "$?"
}
Note that kw_build_cpu_scaling_monitor is called as a program/function
defined in the container. So, before starting the containers, we install
kw_build_cpu_scaling_monitor using a Containerfile for each supported Linux
distribution (Debian, Fedora, and Archlinux). Using the Debian
distribution as an example, here’s how the test is configured in the
Containerfile_debian:
FROM docker.io/library/debian
RUN apt update -y && apt upgrade -y && apt install git -y
COPY ./clone_and_install_kw.sh .
RUN bash ./clone_and_install_kw.sh
# Copy scripts from the "scripts/" folder to a temporary directory
COPY scripts/ /tmp/scripts/
# Grant execution permissions to the copied scripts
RUN chmod +x /tmp/scripts/*
# Move the scripts to /bin
RUN mv /tmp/scripts/* /bin/
For context, the kworkflow project directory structure is as follows:
The goal is to copy all scripts from the scripts/ folder, such as
kw_build_cpu_scaling_monitor, into the container. By creating specific
scripts and copying them to the container’s /bin directory, we can execute them
directly as commands.
With this in mind, let’s examine the script that tests the --cpu-scaling
feature. The main idea is to calculate the CPU usage while the kw build
--cpu-scaling 50 command is running to check if the feature is functioning
correctly.
To analyze the code inside the kw_build_cpu_scaling_monitor script, let’s
break it down into parts.
1. Introduction and Initial Setup
First, we define the essential arguments and variables for the script. This
includes the --cpu-scaling option, which determines the percentage of CPU to be
used, and the kw build command to be monitored.
# Check if an argument is provided
if [[ "$#" -eq 0 ]]; then
printf 'Usage: %s <cpu_scaling_value>\n' "$0"
exit 1
fi
# Assign the argument to CPU_SCALING
declare -g CPU_SCALING="$1"
declare -g CPU_USAGE_FILE='/tmp/cpu_usage.txt'
declare -g KW_BUILD_CMD="kw build --cpu-scaling ${CPU_SCALING}"
2. CPU Usage Monitoring
In this section, we monitor the CPU usage during the execution of kw build.
We use a function that collects data from the CGROUP filesystem,
calculating the average CPU usage based on the following formula:
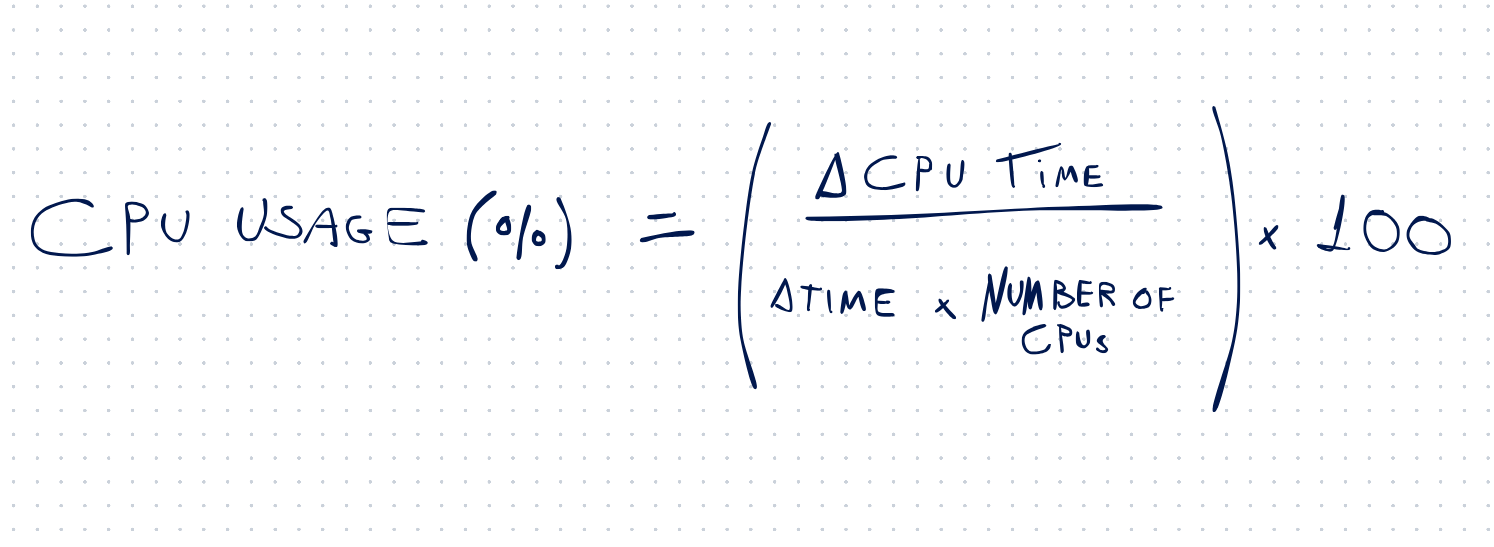
function monitor_cpu_usage()
{
local cgroup_path='/sys/fs/cgroup/cpu.stat'
local duration=30
local interval=5
local end
local initial_usage
local final_usage
local usage_diff
local usage_diff_sec
local cpu_count
local cpu_usage_percent
end=$((SECONDS + duration))
while [ $SECONDS -lt $end ]; do
initial_usage=$(grep 'usage_usec' "$cgroup_path" | cut -d' ' -f2)
sleep "$interval"
final_usage=$(grep 'usage_usec' "$cgroup_path" | cut -d' ' -f2)
usage_diff=$((final_usage - initial_usage))
usage_diff_sec=$(printf 'scale=6; %s / 1000000\n' "$usage_diff" | bc -l)
cpu_count=$(nproc)
cpu_usage_percent=$(printf 'scale=2; (%s / (%s * %s)) * 100\n' "$usage_diff_sec" "$interval" "$cpu_count" | bc -l)
printf '%s\n' "$cpu_usage_percent" >> "$CPU_USAGE_FILE"
done
}
3. CPU Usage Average Calculation
Here, the calculate_avg_cpu_usage() function reads the collected values and
calculates the average CPU usage during the build proces
function calculate_avg_cpu_usage()
{
local sum=0
local count=0
while IFS= read -r line; do
sum=$(printf "%.6f" "$(printf "%s + %s\n" "$sum" "$line" | bc -l)")
count=$((count + 1))
done < "$CPU_USAGE_FILE"
if [ "$count" -gt 0 ]; then
avg=$(printf "%.6f" "$(printf "%s / %s\n" "$sum" "$count" | bc -l)")
else
avg=0
fi
printf "%s\n" "$avg"
}
4. Verification and Validation
In this step, we compare the average CPU usage obtained with the expected value (in this case, 50%). It’s important to consider an acceptable error margin in this comparison. CPU time may vary due to several factors such as warming up, context switching, and other system activities. These variations can influence the results, so allowing for a small margin of error helps avoid flaky tests. If the average CPU usage falls outside this margin, the test will fail, ensuring that we account for any variability in the CPU performance.
function check_cpu_usage()
{
local avg_cpu_usage="$1"
local target_cpu_usage="$CPU_SCALING"
local threshold=10
local lower_bound
local upper_bound
lower_bound=$(printf "%.2f" "$(bc <<< "${target_cpu_usage} - ${threshold}")")
upper_bound=$(printf "%.2f" "$(bc <<< "${target_cpu_usage} + ${threshold}")")
# Check if the average CPU usage is outside the expected range
if [[ $(bc <<< "${avg_cpu_usage} < ${lower_bound}") -eq 1 || $(bc <<< "${avg_cpu_usage} > ${upper_bound}") -eq 1 ]]; then
exit 1
else
return 0
fi
}
5. Cancel Build Process
To prevent the build process from continuing after monitoring, the script
terminates all related build processes using pstree to find all subprocesses.
function cancel_build_processes()
{
local pids_to_kill
local parent_pid
local parent_pids
# Using mapfile to populate parent_pids array
mapfile -t parent_pids < <(pgrep -f "$KW_BUILD_CMD" || true)
for parent_pid in "${parent_pids[@]}"; do
if [ -n "$parent_pid" ]; then
# Using read with IFS to populate pids_to_kill array
IFS=' ' read -r -a pids_to_kill <<< "$(pstree -p "$parent_pid" | grep -o '([0-9]\+)' | grep -o '[0-9]\+')"
printf "Cancelling PIDs: %s\n" "${pids_to_kill[@]}"
printf "%s\n" "${pids_to_kill[@]}" | xargs kill -9
fi
done
}
6. Script Execution
Finally, the script runs the kw build command in the background, monitors CPU usage, calculates the average, checks if it is within the error margin, and cancels processes at the end.
# Start the build command in the background
eval "$KW_BUILD_CMD" &
# Wait a short period to ensure the kw build process is running
sleep 30
# Monitor CPU usage while the process is running
monitor_cpu_usage
# Cancel the build processes and their subprocesses
cancel_build_processes
# Calculate the average CPU usage
avg_cpu_usage=$(calculate_avg_cpu_usage)
printf "Average CPU usage during build: %.2f%%\n" "$avg_cpu_usage"
# Check if the average CPU usage is within the expected range
check_cpu_usage "$avg_cpu_usage"
# Clean up the CPU usage file
rm $CPU_USAGE_FILE
Validating the workflow with assert_equals_helper
Returning to our cpu-scaling option test function:
function test_kernel_build_cpu_scaling_option()
{
local build_status
local build_result
local build_status_log
local cpu_scaling_percentage=50
container_exec "$CONTAINER" "cd ${KERNEL_TREE_PATH_CONTAINER} && kw_build_cpu_scaling_monitor ${cpu_scaling_percentage} > /dev/null 2>&1"
assert_equals_helper "kw build --cpu-scaling 50 failed for ${CONTAINER}" "(${LINENO})" 0 "$?"
}
The test runs inside a container, where the script monitors CPU usage while kw
build --cpu-scaling 50 is executed. The check_cpu_usage function compares
the average CPU usage with the expected value and, based on this, returns 0
(success) or 1 (failure). The result is then verified by
assert_equals_helper, ensuring that the behavior is as expected.
With this, we conclude the validation of the CPU scaling feature. If the
check_cpu_usage() function returns 0, the test is considered successful,
validating that the CPU scaling functionality of kw build is working correctly.
Conclusion
kw build is one of the core features of kw, so integration testing for it is
crucial to ensure the tool’s robustness and reliability, especially when
dealing with different environments and various configuration options. The
adoption of Podman Containers and the shUnit2 framework allowed for a
structured and efficient approach to these tests. Additionally, optimizing the
testing environment and rigorously checking results ensure that kw build
continues to function as expected, even under varying conditions. Adjusting the
test execution strategy to reduce time and resource consumption was a critical
decision for the project.
Furthermore, the foundational work on the infrastructure for testing kw build
has been laid. This will facilitate future expansions of the testing suite,
making it easier to test other feature workflows and ensure comprehensive
coverage across the tool.