Introducing SQLite3 to kw
Written by David Tadokoro , published on August 23, 2023Around May, I had the opportunity of helping to introduce a Database Management System (DBMS) to a project that used a file-based database. The DBMS was SQLite3 and the project was kw. This post describes my experience.
File-Based Databases
In a quick Google search, I found that file-based databases are also called flat file databases. But what are file-based databases? It’s the most naive, but it can also be the most agile method of implementing a database on an application.
No matter your level of experience in programming, you probably faced the problem of having to store data persistently. In other words, your application manipulates data (one can argue that this is the only thing computers do) and you had to store this data not on main memory but on persistent memory, maybe because the application didn’t run continuously and it has to store data in a persistent memory.
The most straightforward way to solve this is by creating a file and outputting the app data to this file. It can be a plain text file or a binary file, but, in any case, you have to manage two things:
- Where the file is being stored, to both insert and retrieve data from the right file.
- This “format” of how the data is being stored to correctly manipulate it.
These add more complexity that will be absorbed by the application. On the other hand, it’s “self-contained” in the application, you don’t have to learn the ins and outs of a DBMS, and you don’t have to introduce it in your application to solve your problem. I personally think that, in some cases, this is the best approach.
The structure described above is my understanding of a file-based database. At least, this was the structure present in kw.
kw old database
The following description is based on the
unstablebranch at commit#a42592a. You can check kw’s repo at this state here.
As an XDG-compliant application,
kw stores its user-specific data files at ~/local/share/kw. In this sense,
there were three sub-directories ~/local/share/kw/statistics, ~/local/share/kw/pomodoro,
and ~/local/share/kw/configs that functioned like databases. The first stored files
related to any statistic collected by kw. The second stored files related to Pomodoro
sessions (from kw pomodoro).
The third one stored Linux kernel .config files and metadata for the kw kernel-config-manager feature.
For statistics, a file statistics/<year>/<month>/<day> represented statistics
collected at <month>/<day>/<year>. For example, a line
build 497
in a file statistics/23/08/23, meant that a kw build command ran on August 23
of 2023 and lasted for 8 minutes and 17 seconds (497 seconds).
kw pomodoro had this same file structure that represented dates, with each line
representing an entry. Differently from the statistics database though, each line/entry
was comma separated, had a different number of attributes, and also had an optional
attribute. On top of that, there was a file ~/local/share/kw/pomodoro/tags for
storing Pomodoro tags and a file ~/local/share/kw/pomodoro_current.log for the active
Pomodoro timeboxes.
I could also explain the intricacies of the kw kernel-config-manager database
(which had even more particularities), but it would probably be tiresome for you
the reader.
The point may be already clear: although functional, each feature had to implement its own database with its own details. This made the code hard to scale and more coupled with these particularities of where and how the data was stored.
The right DBMS
DBMSs are really vast and diverse, proposing different solutions for different problems. The people involved in kw knew that the introduction of a DBMS was necessary and agreed on some requisites for the system:
- Be Free Libre and Open Source Software (FLOSS).
- Have a CLI interface for easy integration with Bash, as we want to maintain kw’s codebase in pure Bash wherever possible.
- Have a small footprint.
- Run on user space.
- Be a Relational DBMS.
- Be portable, something easy to set up.
In the end, the DBMS that was chosen was SQLite3, as it was Public Domain (not exactly FLOSS, but much better than proprietary), had a CLI interface, sized less than 1 MB, ran on user space, and was Relational. We also considered PostgreSQL and TinyDB, but they didn’t qualify in one or more of the requirements.
kw new database
The following description is based on the
unstablebranch at commit#02e89e2, which was the last commit of the PR that introduced SQLite3 to kw. You can check kw’s repo at this state here.
First, I must point out that kw’s database schema, with all the tables, views, indexes,
and triggers was a wonderful job made by Rubens Gomes Neto
and Magali Lemes and is described at database/kwdb.sql.
Below is a diagram that is part of the theoretical model of the database. It is in
Portuguese, and it doesn’t include entities or relationships relating to kw kernel-config-manager,
but it exemplifies how the modeling of statistics and Pomodoro sessions was made.
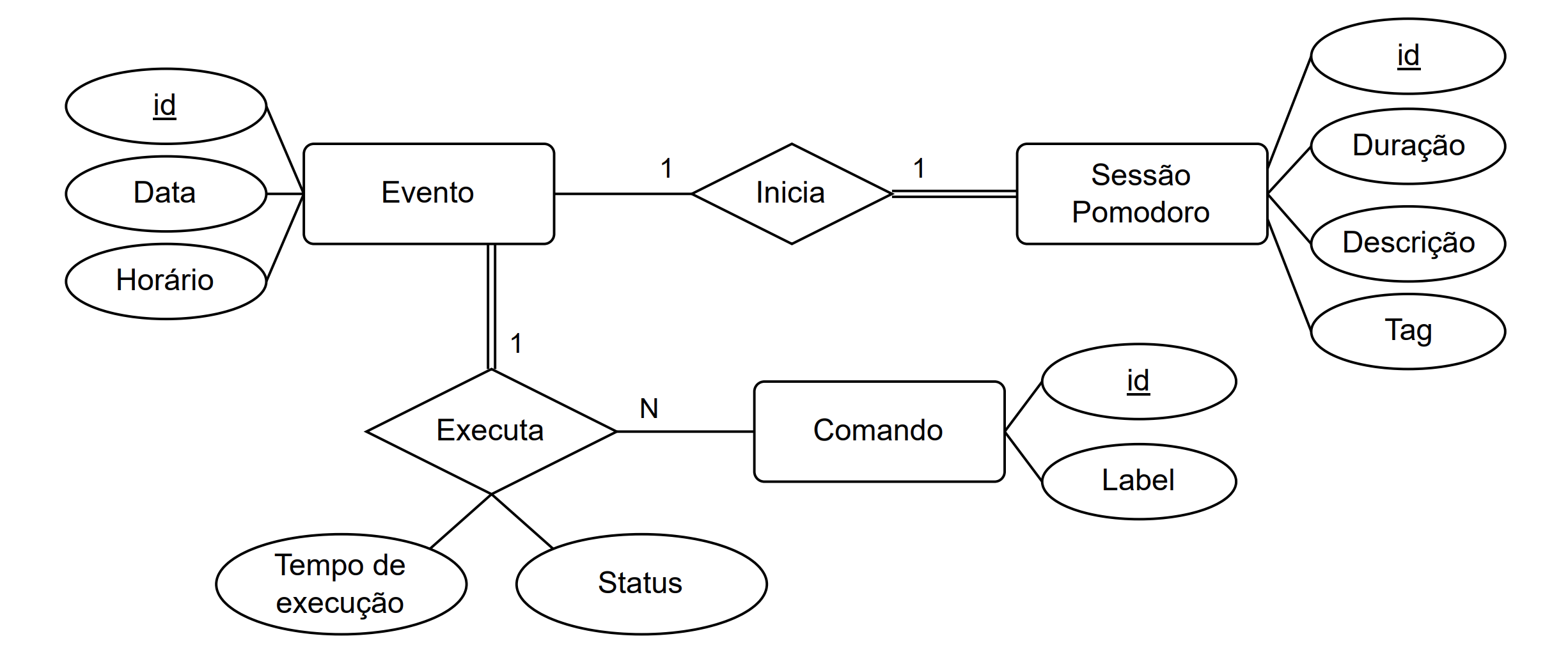
The diagram is an Entity-Relationship Diagram (ERD) in which, rectangles represent entities that have attributes associated (circles), and diamonds represent relationships (that can also have attributes) between these entities.
Take the entity Sessão Pomodoro (Pomodoro Session) that represents a Pomodoro timebox, which has a duration, tag and, optionally, a description. You may think that it lacks a timestamp, but the reason is that a Pomodoro timebox has a relationship Inicia (Starts) with an Evento (Event), which actually has a timestamp associated. This may not be completely straightforward to understand but think that if multiple timeboxes are associated with one event, having one instance of the event, rather than each timebox absorbing its attributes, reduces duplication and detaches an event from a timebox, so it can be associated with other types of entities. You can check a more detailed explanation in Rubens Gomes Neto Capstone Project, from which the diagram was taken.
It is important to notice that this is the theoretical database model and the DB’s
schema is considered the logical database model, which is the one that SQLite3 actually
“understands” (as said previously, this schema can be checked at database/kwdb.sql).
Other than modeling the DB’s schema, the introduction meant adapting all impacted features, which were:
kw build.kw deploy.kw kernel-config-manager.kw pomodoro.kw report.kw backup.
With the SQLite3 introduction, instead of having multiple subdirectories at ~/.local/share/kw
for each of its “databases”, now the whole kw DB is stored in a single file~/.local/share/kw/kw.db.
This means that the code “doesn’t need to know” anymore about where the data was
stored, reducing its complexity.
Also, library functions were created as wrappers for SQLite3 calls, like the function
insert_into <table> <columns> <entries>
that (roughly) wrapped the command
sqlite3 "INSERT INTO <table> <columns> VALUES <entries>;"
Although each “different database” still has its own entities and relationships, the way that any data is inserted, updated, and deleted is the same by using these library calls. That standardizes how the data is stored, which further reduces its complexity.
Besides these benefits that were the actual motive for the DBMS introduction, a collateral benefit should be noted: performance. As kw used to manage many plain-text files sprinkled around many directories and subdirectories, these I/O operations that were coordinated by kw can’t compete with a system that focuses on database management accessing a single binary file.
To further investigate this performance bump, I ran the command
perf stat --repeat 10 ./run_tests.sh
both before and after SQLite3 introduction for measuring the time it takes to run kw’s whole test suite.
Before the introduction, the perf stat output was
55.084 +- 0.136 seconds time elapsed ( +- 0.25% )
and after the introduction, the perf stat output was
38.9413 +- 0.0955 seconds time elapsed ( +- 0.25% )
which is almost a 30% decrease in time.
Conclusion
In short, SQLite3 introduction to kw can be considered a success that had an immediate impact on both scalability and performance. Anyhow, I think that the long-term payoff will be greater as managing and extending code that uses the kw new database will be easier and less daunting than it once was.